Comment gérer le Robots.txt en SEO ?

Les propriétaires de site ne bénéficient pas forcément de compétences techniques pour gérer leur propre site web. Leur priorité c’est de produire du contenu dans le but d’informer, de vendre des produits ou de proposer des services. Le fichier robots.txtFichier texte à la racine d'un site indiquant aux robots quelles pages explorer ou ignorer. ne représente sans doute pas grand chose pour eux.
Quelques explications s’imposent pour que tous puissent comprendre l’intérêt d’un fichier robots.txt tout en ayant également des notions pour mieux le gérer.
Qu'est-ce qu'un fichier Robots.txt ?
Le fichier robots.txt rassemble les URLUniform Resource Locator. Adresse unique d'une page web. Une URL optimisée est courte, descriptive et contient le mot-clé. constituant votre site internet. Ce fichier texte sert d’indicateur aux robots d’explorations. Il est déterminant pour communiquer avec les robots sur la prise en compte des différentes URL de votre site.
PrAlgorithme historique de Google évaluant l'importance d'une page selon ses backlinks. Toujours utilisé en interne.ésent à la racine du site, un fichier robots.txt se présente sous cette forme :

Utilisation du fichier robots.txt
https://www.youtube.com/watch?v=2V44ttqDbLM
Un fichier robots.txt a de multiples fonctionnalités. Découvrez-les ci-dessous :
Demander aux robots d’exploration d’ignorer le contenu de votre site
User-agent: * Disallow: /
C’est une information claire et précise située dans le fichier robots.txt, indiquant aux robots d’explorationProcessus par lequel les robots des moteurs de recherche parcourent et analysent les pages web. de ne pas analyser les pages du site.
Autoriser les robots d’exploration Web à accéder à l’ensemble du contenu de votre site
User-agent: * Disallow:
C’est une commande intégrée dans un fichier robots.txt pour indiquer aux robots qu’ils peuvent explorer toutes les pages du site.
Demander le blocage d’un robot d’exploration spécifique à partir d’un dossier précis
User-agent: GooglebotRobot d'exploration de Google qui parcourt le web pour découvrir et indexer les pages. Disallow: /exemple-dossier-a/
Cette formule de commande, présente dans un fichier robots.txt, demande à Googlebot de faire abstraction des pages contenant le dossier (/exemple-dossier-a/).
Demande de blocage d’un robot d’exploration Web déterminé, à partir, d’une page spécifique
User-agent: Bingbot Disallow: /exemple-dossier-a/page-bloquer.html
Cette formule de code introduite dans un fichier robots.txt informe le robot d’exploration Bingbot de ne pas explorer la page citée. /exemple-dossier-a/page-bloquer.html
Exemple d’un fichier robots.txt avec des instructions multiples
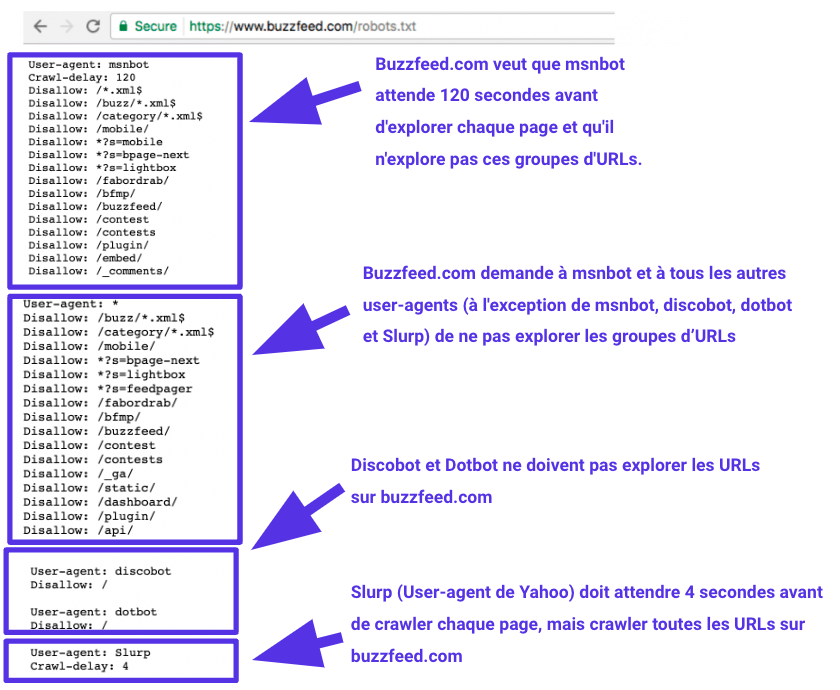
Quel est le fonctionnement d’un fichier robots.txt ?
La mission des moteurs de recherche, c’est l’exploration continuelle du web. Tout nouveau contenu est exploré, analysé puis indexé. La page de site est ensuite visible et accessible pour tous les internautes, via la barre de recherche du moteur (Google ou un autre).
Les robots des moteurs de recherche atterrissent sur les nouvelles pages des sites par l’intermédiaire des liens. Tous les jours, des milliers de pages web sont parcourues. Cette action est nommée “le crawling”.
Avant d’effectuer son exploration, le robot recherche la présence d’un fichier robots.txt. Celui-ci répertorie toutes les instructions liées à l’exploration ou la non-exploration des différentes URL du site.
Tout cela semble trop technique ? Faites appel à une agence SEO technique comme Slashr !
Lexique du fichier robots.txt
Le lexique du fichier robots.txt est une syntaxe regroupant les directives de codage rattaché aux robots d’explorations.
- User-agent : nom que l’on donne aux robots d’exploration Web auxquels vous donnez des instructions d’exploration. Ils sont nombreux. Retrouvez la liste des Users-agents ici.
- SitemapFichier XML listant toutes les URLs d'un site pour faciliter leur découverte par les moteurs de recherche. : fichier regroupant toutes les URL d’un site. Notez que ce type de fichier est lisible par Google, Yahoo, Ask et Bing.
- Disallow : terme désignant la commande qui demande à un User Agent de ne pas explorer une URL Une seule ligne « Disallow: » est autorisée pour chaque URL.
- Allow : directive spécifique au robot Googlebot servant à notifier l’accès à une page (ou à un sous-dossier) même si l’accès à la page parent n’est pas autorisé.
- Crawl-delay : action déterminant le temps d’attente avant le chargement de la page et son exploration. Notez que Googlebot n’est pas en mesure de comprendre cette commande mais la vitesse peut être définie à partir de votre Google Search ConsoleOutil gratuit Google pour surveiller et optimiser la présence d'un site dans les résultats de recherche..
Un fichier robots.txt a-t-il un rôle important ?
Le fichier robots.txt a la charge de gérer le contrôle des robots d’indexationProcessus par lequel Google ajoute une page à sa base de données pour qu'elle puisse apparaître dans les résultats., évitant ainsi l’indexation de pages non destinées aux internautes. Ces pages risquent de plus, de surcharger inutilement votre site.
Récapitulatif des raisons justifiant l’utilisation d’un fichier robots.txt :
Contrôle permanent sur l’exploration des robots
Grâce au fichier robots.txt, vous avez le contrôle permanent des pages à explorer et à indexer. Certaines pages ne présentent aucun intérêt à être indexée.
Il s’agit, pour un site vitrine ou un blog, des pages suivantes :
- Les mentions légales du site
- La politique de gestion des cookies
- Les pages d’archives
- La politique de confidentialité
Pour un site e-commerce, les pages à ne pas indexer sont :
- La page « Panier »
- La page « Mon Compte »
- La page « Validation de la Commande »
- Les conditions générales de vente (CGV)
- Les mentions légales
- Les conditions générales d’utilisation (CGU)
Meilleure gestion de la charge du serveur
Suite à un trop gros volume de demandes d’exploration d’URL, le serveur peut être en surcharge. En répertoriant les pages devant ou non être crawlées, vous garantissez à votre site une expérience utilisateurUser Experience. Qualité de l'expérience vécue par un utilisateur sur un site. Facteur de ranking indirect. et des performances idéales.
Protection de la confidentialité
Le fichier robots.txt présente l’avantage d’exclure de l’exploration des éléments demandant une confidentialité particulière. Non indexées, ces URL resteront privées.
Optimisation du budget de crawl
En présence d’un fichier robots.txt, les robots d’exploration se concentrent sur l’analyse des pages essentielles du site. L’indexation et le référencement des pages n’en sont que plus rapides. Cela permet d'optimiser le budget crawl.
Besoin d'aide avec votre SEOSearch Engine Optimization. Ensemble des techniques visant à améliorer le positionnement d'un site web dans les résultats naturels des moteurs de recherche. ? Faites appel à une agence de référencement naturel à Lille.
Comment créer un fichier robots.txt ?
Créer un fichier robot.txt ne pose pas de réels problèmes. Cet article proposé par Google décrit les différentes étapes auxquelles vous allez être confronté pour créer votre fichier robots.txt.
Les sites fonctionnant avec un programme informatique (CMS) proposent généralement différentes solutions pour créer votre fichier robots.txt.
Créer son fichier Robots.txt sous Shopify
- Connectez-vous sur la plate-forme Shopify
- Accédez au tableau de bord de votre site puis à votre boutique en ligne.
- Cliquez sur les 3 petits points à côté de votre thème
- Cliquez sur l’onglet « Modifier le Code »
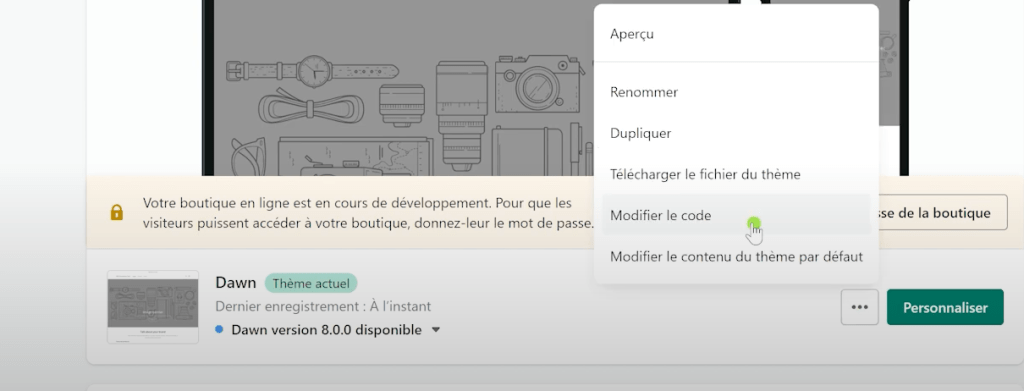
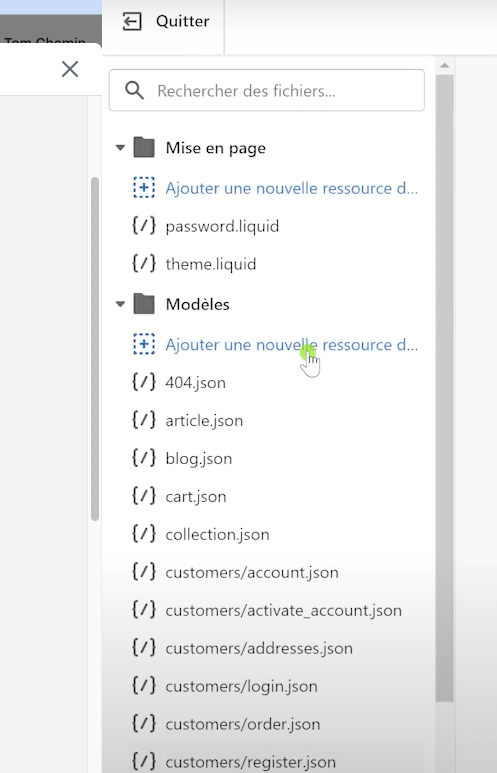
- Ajouter une nouvelle ressource du type : modèle
- Sélectionner le modèle robots.txt
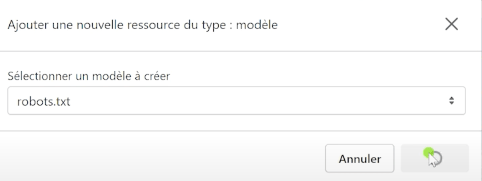
Vous pouvez alors procéder à une modification ou ajouter de nouvelles directives à votre robots.txt.
Création d’un fichier Robots.txt sous WordPress
La gestion de votre fichier robots.txt via WordPress est dépendante de plugins tels que :
- Yoast SEO
- All in One SEO Pack
Choisissez un plugin, installez-le et activez-le à partir de votre tableau de bord sous WordPress.
- Accédez aux paramètres du plugin puis, recherchez l’option Robots.txt.
- Établissez votre fichier robots.txt à l’aide de l’interface du plugin.
Création d’un fichier Robots.txt sous Prestashop
- Connectez-vous à la page d’administration de votre boutique Prestashop.
- Accédez à la section« Préférences »
- Sélectionnez « SEO &Accelerated Mobile Pages. Framework Google pour créer des pages mobiles ultra-rapides (moins utilisé aujourd'hui).; URL »
- Dans l’onglet « SEO & Indexing », recherchez la section « Robots.txt file ».
- Éditez votre fichier robots.txt.
- Enregistrez les modifications.
Tags
SEO Consultant
Tom est consultant SEO chez Slashr. Il accompagne les entreprises dans l'optimisation de leur visibilité organique avec une approche technique et data-driven.
Voir tous ses articlesArticles recommandés
Siloing SEO : Comment organiser son contenu en silo facilement ?
Le Siloing est une méthode stratégique pour structurer l’architecture d’un site web. Quand on sait que tous les moteurs de recherche apprécient les sites bien c...
L’arborescence SEO : la structure que Google (et vos visiteurs) attendent de vous
Vous avez bossé vos mots-clés, publié du contenu de qualité, peaufiné vos balises… et pourtant, votre site ne décolle pas ? Et si le vrai problème, c’était… l’o...
Article SEO : Comment les rédiger, les bonnes pratiques, pourquoi en faire
Vous avez sûrement déjà entendu dire que « le contenu est roi ». C’est sympa comme phrase, mais en vrai… un roi tout seul dans son château, ça ne sert pas à gra...


