Crawl budget SEO : Ce que Google explore… ou ignore

🧠 1. Le budget de crawl, c’est quoi au juste ?
En SEOSearch Engine Optimization. Ensemble des techniques visant à améliorer le positionnement d'un site web dans les résultats naturels des moteurs de recherche., pas d’indexationProcessus par lequel Google ajoute une page à sa base de données pour qu'elle puisse apparaître dans les résultats. = pas de positionnement. Et pour qu’une page soit indexée, elle doit d’abord être vue par Google. C’est là qu’entre en scène le budget de crawlNombre de pages que Googlebot peut et veut crawler sur un site dans un temps donné..
🧮 Pour faire simple :
Le budget de crawl, c’est la combinaison entre ce que Google peut explorer sur votre site (capacités techniques), et ce qu’il a envie d’explorer (intérêt SEO perçu).
Deux composantes à comprendre :
- Crawl rate limit (La capacité de crawl) : la limite physique. Si votre serveur rame, sature ou répond mal, Google ralentit. Trop d’erreurs = moins de crawl.
- Crawl demand (La demande de crawl) : la logique SEO. Si une page est populaire, fraîche, utile… elle sera visitée plus souvent. Sinon ? Elle sera vite ignorée.
Autrement dit :
🔌 Un serveur lent = Google ralentit la cadence.
🥱 Des pages sans valeur ou rarement mises à jour = Google passe moins souvent, voire jamais.
Résultat ? Google alloue un quota d’attention à chaque site. Et ce quota, vous pouvez l’optimiser ou le flinguer.
🔎 Et plus votre site est gros (catalogue e-commerce, média, marketplace…), plus le budget de crawl devient un levier critique. Vous ne voulez pas que vos meilleures pages soient invisibles pendant que Google explore vos filtresSystème de filtres (taille, couleur, prix) générant de nombreuses URLs. Nécessite une gestion SEO., vos pages vides ou vos 404Code HTTP indiquant qu'une page n'existe pas. Trop d'erreurs 404 nuisent au crawl budget..
Le crawl le vous parle pas ? Consultez notre article sur le processus de crawling.
Vous pouvez vérifier le nombre de pages indexées de votre site dans Google Search ConsoleOutil gratuit Google pour surveiller et optimiser la présence d'un site dans les résultats de recherche., sous la section "Couverture de l'index".
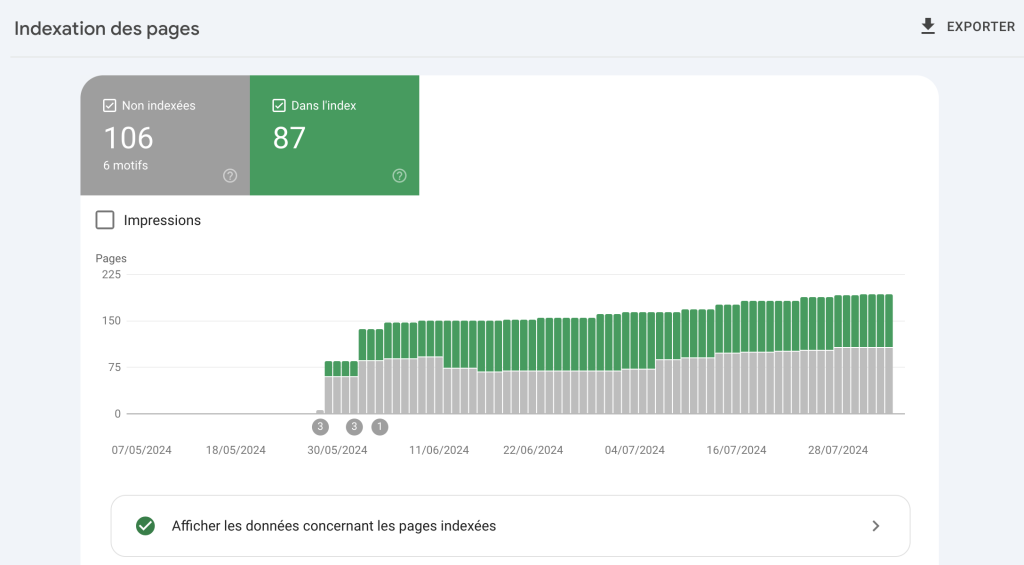
💣 Ce qui flingue votre budget de crawl (et comment Google réagit)
Quand on parle de budget de crawl, la vraie question n’est pas « Est-ce que Google veut crawler mon site ? », mais plutôt : « Est-ce que je lui facilite la vie ou est-ce que je le fais fuir ? »
Parce que même avec un site bien noté côté popularité, si l’explorationProcessus par lequel les robots des moteurs de recherche parcourent et analysent les pages web. technique est chaotique, GooglebotRobot d'exploration de Google qui parcourt le web pour découvrir et indexer les pages. va très vite ralentir la cadence, voire décrocher. Voici ce qui ruine votre budget de crawl en silence :
🐢 Serveur lent ou instable = Google freine
Google a une tolérance très basse aux serveurs qui rament.
👉 Si vos temps de réponse montent au-dessus de 1s, il ralentit automatiquement sa fréquence de passage pour ne pas surcharger le serveur.
Et s’il rencontre trop de 5xx ? Il arrête tout simplement de crawler.
⏱️ BenchmarkAnalyse comparative des performances SEO par rapport aux concurrents. :
- Temps de réponse < 500Code HTTP indiquant une erreur côté serveur. Impacte négativement le crawl et l'expérience utilisateur. ms → crawl boosté
- Temps > 1000 ms → crawl ralenti de 130% (source : Botify)
💡 Astuce : il est possible de vérifier le TTFB (time to first byteTime To First Byte. Temps entre la requête et la réception du premier octet de réponse du serveur., le temps de réponse de votre serveur) que Googlebot enregistre directement dans la Search console. Le rapport est disponible dans "Paramètres" puis "Statistiques sur l'exploration". Je vous conseille de conserver un temps de réponse moyen inférieur à 500 MS.
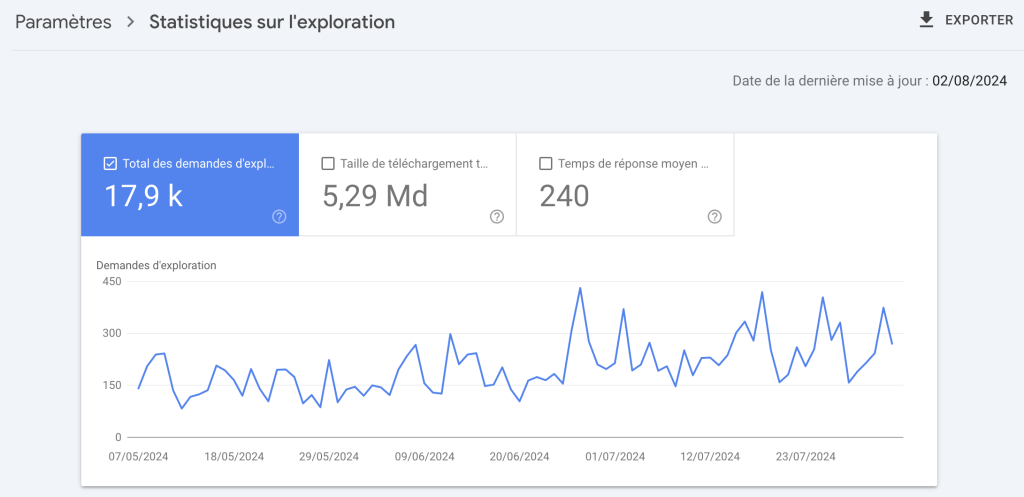
🔁 Redirections inutiles & boucles = perte sèche
Les chaînes de redirection de 3 ou 4 hops (oui, on en voit encore en 2025) font perdre du temps à Googlebot.
Et chaque redirection SEO, c’est une page de moins visitée dans son budget. Pire, les boucles peuvent bloquer l’exploration totale de segments entiers.
✅ Règle : 1 redirection max (301Redirection permanente transférant le jus SEO de l'ancienne URL vers la nouvelle. directe), jamais plus.
🔗 Pages orphelines = invisible pour Google
Une page sans lien entrantLien provenant d'un site externe pointant vers votre site. Facteur de ranking majeur. (depuis le site ou le sitemap) n’existe tout simplement pas aux yeux du robot. Même si elle est pertinente, même si elle est optimisée.
➡️ Et si vous en avez des centaines ou milliers, c’est autant d’énergie que Google ne sait pas où dépenser.
👉 Résultat : il tente des crawl randoms ou se désintéresse.
💨 Javascript mal géré = gaspillage de ressources
Les sites full JS mal configurés obligent Google à faire deux passages :
- D’abord pour récupérer l’HTML vide
- Ensuite pour faire le rendering (interprétation JS)
Sauf que ce deuxième passage… ne se fait pas toujours. Et même s’il se fait, il arrive beaucoup plus tard que le crawl HTML brut.
⛔ Mauvais JS = pages non explorées ou explorées trop tard.
Utilisez prerender, SSR ou simplifiez au max pour les pages stratégiques.
📉 Contenu dupliqué, thin content, pages inutiles
Si vous avez :
- 50 déclinaisons d’un même produit avec une URL chacune
- des filtres qui génèrent des URLs indexables à l’infini
- des listings paginés crawlables mais sans valeur ajoutée…
Alors Google perd littéralement son temps et son énergie sur du contenu peu utile.
Il n’ira pas voir les pages qui comptent, car vous l’ennuyez avant qu’il y arrive.
👉 Faites particulièrement attention au spider trap (piège à robot), qui est absolument dévastateur pour votre budget crawl.
📈 Ce qui fait grimper la demande de crawl
À l’inverse des erreurs techniques ou structurelles qui brident le crawl, certaines pratiques peuvent donner envie à Google de revenir plus souvent et d’explorer plus profondément. Le crawl, ce n’est pas un droit — c’est un signal de confiance. Et comme toute confiance, ça se gagne.
Voici les leviers les plus efficaces pour booster cette demande :
🔗 La popularité, toujours en pole position
Plus une page reçoit de liens (internes et surtout externes), plus elle est perçue comme importante. Et plus Googlebot viendra la visiter.
👉 Backlinks frais = boost direct du crawl.
👉 Maillage interneEnsemble des liens entre les pages d'un même site. Distribue le jus SEO et guide les utilisateurs. stratégique = propagation de la popularité vers des pages profondes.
👉 Trafic externe = augmentation de l'autorité au global de votre site et donc du crawl de google
Une page en page 5 de pagination peut devenir régulièrement crawlée… si elle reçoit un lien depuis une page très populaire du site.
📰 La fraîcheur, mais pas n’importe comment
Google adore le contenu mis à jour. Mais pas les faux updates.
Une vraie mise à jour (ajout de sections, nouveaux visuels, enrichissement sémantique) stimule la demande de crawl. Google revient vérifier s’il doit reclassifier la page.
💡 Astuce : ajouter un bloc “mis à jour le…” dans le code source et le visible renforce le message.
✅ Le contenu perçu comme “utile”
L’algoProgramme informatique utilisé par les moteurs de recherche pour classer les pages web. Google utilise plus de 200 facteurs de ranking. de Google évolue : aujourd’hui, l’expérience utilisateurUser Experience. Qualité de l'expérience vécue par un utilisateur sur un site. Facteur de ranking indirect. compte dans les signaux indirects qui influencent le crawl.
➡️ Scroll depth élevé, bon TTV (Time to View), clics secondaires…
➡️ Pages avec engagement = pages plus crawlées = pages mieux positionnées.
📊 Googlebot semble de plus en plus piloté par les insights Navboost (cfMétrique Majestic mesurant la quantité de liens pointant vers un site.. notre article à ce sujet), ce qui crée une vraie boucle “intérêt utilisateur → intensité de crawl”.
🧭 Une architecture limpide
Un site bien structuré, c’est un site où Googlebot ne se perd pas.
Si votre sitemap est cohérent, que les menus sont clairs, que les liens sont contextuels et hiérarchisés : vous envoyez un signal de fiabilité.
👁️🗨️ Google prAlgorithme historique de Google évaluant l'importance d'une page selon ses backlinks. Toujours utilisé en interne.éfère crawl un site structuré à 10 000 pages qu’un fouillis de 1 000 URLsUniform Resource Locator. Adresse unique d'une page web. Une URL optimisée est courte, descriptive et contient le mot-clé. inutiles.
📊 Ce que montrent les chiffres (et pourquoi c’est pas que théorique)
Le budget de crawl, c’est pas juste un concept flou de SEO technique. C’est un levier quantifiable. Et les chiffres parlent d’eux-mêmes.
💀 50 % des pages jamais explorées
Selon une étude de Botify, plus de la moitié des pages des grands sites e-commerce analysés ne sont jamais crawlées par Googlebot. Zéro visite, zéro indexation, zéro chance d’être visible.
👉 Source : Botify
⚡ Temps de chargement : <500 ms = 2x plus de crawl
Toujours selon Botify, les pages qui se chargent en moins de 500 ms sont 2 fois plus crawlées que celles qui prennent plus de 1 seconde. Google n’aime pas attendre.
👉 Source : même étude Botify
📚 Les pages longues sont mieux crawlées
Autre insight intéressant : les pages avec plus de 2500 mots reçoivent significativement plus de passages de Googlebot. À l’inverse, les pages très courtes (moins de 300 mots) sont largement ignorées.
👉 Source : Crawl Budget Optimization For Classified Websites
💡 Cas Skroutz.gr (filiale de PriceRunner – 25M pages au départ)
En supprimant ou en désindexant massivement leurs pages inutiles (search internes, combinatoires, etc.), ils sont passés de 25M à 7,6M de pages indexées.
👉 Résultat : Google a crawlé plus fréquemment les pages importantes, réduisant le temps d’indexation de plusieurs mois à quelques jours.
📉 Le trafic est passé de 63M à 70M de clics mensuels.
🔁 38,28 % des pages en noindexDirective indiquant aux moteurs de ne pas indexer une page. ont continué à être crawlées pendant 6 mois après le changement.
👉 Source : étude Skroutz – SEO case study 2019
🛠️ 5. Optimiser son budget de crawl (concrètement)
🚧 Technique : vitesse, erreurs 5xx, JS, redirections
Quand Googlebot explore votre site, il teste sa résistance. Un site lent ou fragile, c’est un site qu’il va rapidement mettre de côté. Quelques points critiques à surveiller :
- Vitesse de chargement : une page qui dépasse 1 seconde de temps de réponse côté serveur peut voir son crawl chuter brutalement. Selon Botify, les pages <500 ms sont 130% plus crawlées que celles >1000 ms.
- Erreurs serveur 5xx : elles indiquent à Googlebot que votre site n’est pas stable. Trop d’erreurs = baisse de fréquence de crawl.
- JavaScriptLangage de programmation web. Son mauvais usage peut bloquer l'indexation par les moteurs de recherche. mal géré : si Google doit attendre le rendu JS pour voir le contenu, vous gaspillez des ressources. Préférez le contenu visible dans le HTML brut.
- Chaînes de redirections : une redirection simple passe, une chaîne de 3 hops ou plus = perte de jus + coût de crawl inutile.
👉 Pour faire simple : Google n’aime pas les sites mous.
🧭 Structure : plan du site logique, profondeur < 3 clics, liens contextuels
Un site bien structuré, c’est comme une carte GPS pour les robots.
- Profondeur maximale : 3 clics entre la home et les pages stratégiques. Plus, c’est risqué.
- Plan du site clair : évitez les structures trop plates ou trop profondes. Un site e-com avec 3000 produits peut garder une architecture simple avec un bon système de catégories et facettes.
- Liens contextuels : ne comptez pas que sur les menus. Les liens dans les textes ou blocs associés sont bien mieux compris par Googlebot.
🧠 Petit rappel : ce n’est pas la quantité de liens qui fait tout, mais leur pertinence sémantique et leur accessibilité.
✂️ Élagage : supprimer / rediriger / désindexer intelligemment
Si votre site a plus de 10k pages, il y a fort à parier qu’un bon % est inutile côté SEO. Il faut faire le ménage :
- 404 valides : parfois normales, mais trop nombreuses = budget gaspillé.
- Pages à zéro trafic ou crawlées mais non indexées : souvent les pires candidates.
- Produits indisponibles, filtres non indexables, tags de blog oubliés…
➡️ On ne supprime pas à l’aveugle : on analyse logsFichiers enregistrant toutes les requêtes reçues par un serveur, permettant d'analyser le comportement des bots. + trafic + indexation, puis on choisit :
- Blocage via robots.txtFichier texte à la racine d'un site indiquant aux robots quelles pages explorer ou ignorer.
- Suppression pure
- Redirection (301)
- Passage en
noindex - Obfuscation de liens
🧼 Robots.txt, canonical, sitemap XML clean
Les fondamentaux du SEO technique :
- robots.txt : bloquez les répertoires inutiles ou filtrables (params, filtres, résultats de recherche internes…).
- CanonicalBalise indiquant la version principale d'une page en cas de contenu dupliqué ou similaire. : assurez-vous que chaque URL “utile” se canonicalise elle-même, et que les variantes renvoient bien vers leur version principale.
- Sitemap XMLFichier XML listant toutes les URLs d'un site pour faciliter leur découverte par les moteurs de recherche. : uniquement les pages indexables. Pas de 404, pas de pages exclues. Sinon, Google perd confiance.
👉 Un bon sitemap = une promesse tenue à Googlebot. Il ne doit pas mentir.
🧠 Prioriser les pages business et utiles
Si tout est important, rien ne l’est. Votre budget de crawl n’est pas extensible à l’infini.
- Mettez en avant les pages business : catégories, produits clés, guides d’achat, pages pilier.
- Moins de priorité aux pages accessoires (mentions légales, CGV, filtres, tags inutiles…).
- Utilisez l’interconnexion des pages stratégiques pour créer un graphe de crawl efficace.
🔍 6. Les bons outils pour surveiller tout ça
🧰 Google Search Console
La GSC est l'outil parfait si vous n'avez pas le budget pour l'analyse de logs.
- Statistiques de crawl (fréquence, erreurs, délais)
- Couverture d’index
- Inspection d’URL (indexation + rendu)
📁 Analyseurs de logs
Botify, Oncrawl, JetOctopus, Seolyzer…
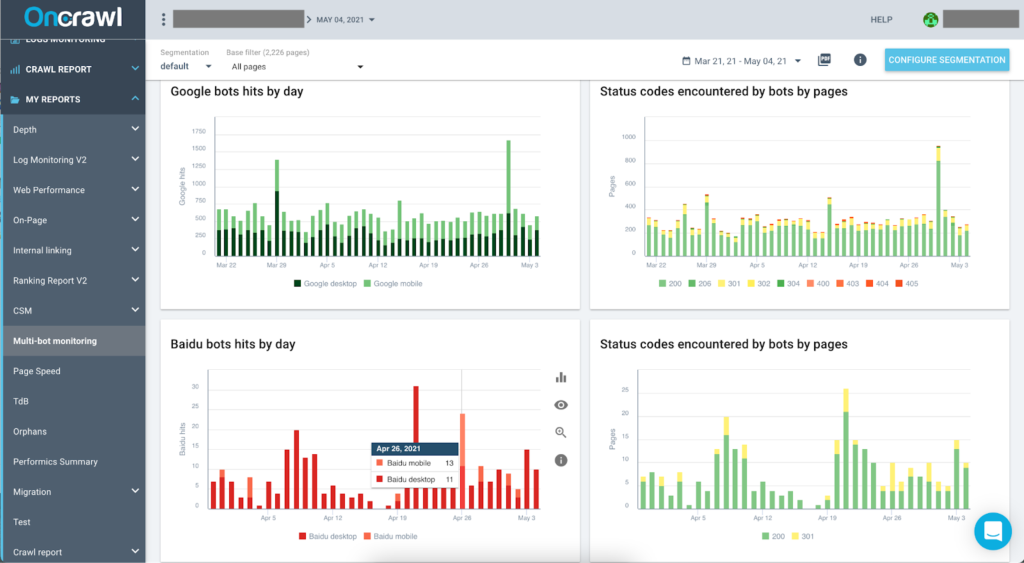
Indispensables pour savoir ce que Google explore vraiment.
Vous saurez quelles pages reçoivent du crawl, à quelle fréquence, et où le robot tourne en rond.
🕷️ Crawlers SEO
Screaming Frog, Sitebulb, Seobserver (partie crawl)

Parfaits pour voir le site comme un bot le voit. Vous pourrez détecter profondeur, erreurs, balises incohérentes, duplication…
💡 La vraie puissance vient du croisement crawler + logs + GSC.
📌 7. Conclusion : Pas de crawl, pas de SEO
Pas de crawl = pas d’indexation = pas de visibilité. Aussi simple que ça.
Et pourtant, le crawl budget reste sous-estimé, même sur des sites à très fort trafic. Optimiser son architecture, nettoyer ses pages mortes, accélérer son serveur… Ce sont des actions à fort ROIReturn on Investment. Retour sur investissement d'une action SEO. pour (ré)activer tout le potentiel SEO d’un site.
🧠 En SEO, il ne suffit pas d’avoir du contenu de qualité. Encore faut-il qu’il soit découvert, crawlé, et indexé.
Tags
Co-fondateur & SEO Director
Benoît Demonchaux est co-fondateur de Slashr, agence de référencement naturel basée à Lille et consultant SEO depuis 6 ans. Avant de créer Slashr, il a exercé en tant qu'éditeur de sites et chef de projets dans une grande agence SEO.
Voir tous ses articlesArticles recommandés
Pagination SEO : laquelle choisir en fonction de son site web ?
La pagination est souvent gérée de façon aléatoire. Pourtant, bien pensée, elle peut booster l’UX, améliorer le crawl de Google, et renforcer la structure SEO d...
Comment améliorer l'indexation de votre site sur Google
Un site non indexé par Google n’a aucun intérêt. Il n’est pas visible dans les résultats de recherche et, il ne génère aucun trafic organique. Votre site est co...
Comprendre le processus de crawling des moteurs de recherche
Vous vous êtes certainement déjà demandé comment les moteurs de recherche comme Google arrivent à classer les pages sur internet et ce peu importe la requête de...


