Comprendre le processus de crawling des moteurs de recherche
Clément Poletti
Vous vous êtes certainement déjà demandé comment les moteurs de recherche comme Google arrivent à classer les pages sur internet et ce peu importe la requête de base. Dans cet article, nous allons découvrir le principe de crawling, son importance, comment il fonctionne et son impact sur le SEO.
Définition et importance du crawling dans les moteurs de recherche
https://www.youtube.com/watch?v=Md7K90FfJhg
Petit vidéo explicative de Matt Cutts qui nous explique comment le crawling fonctionne chez Google.
Qu'est-ce que le crawling ?
Commençons directement dans le vif du sujet, le crawling est un processus automatisé qui est réalisé par des algorithmesProgramme informatique utilisé par les moteurs de recherche pour classer les pages web. Google utilise plus de 200 facteurs de ranking. appelés robots d’indexationProcessus par lequel Google ajoute une page à sa base de données pour qu'elle puisse apparaître dans les résultats. ou spiders.
Ces fameux robots ont pour but de parcourir le Web en suivant des liens d’une page à une autre tout en collectant des données sur ces mêmes pages dans le but d’enrichir la base de données des moteurs de recherche. Il sont aujourd’hui très performants comme par exemple celui de Google qui a pu explorer plus de 130 milliards de pages. On comprend maintenant l’ampleur du travail à effectuer étant donné que 800 000 sites sont créés par jour.
Pourquoi le crawling est essentiel pour les moteurs de recherche
Le crawling est évidemment essentiel pour les moteurs de recherche étant donné qu’il permet de découvrir de nouvelles pages web et de les indexer. Cette pratique est primordiale afin de les rendre accessibles aux utilisateurs lorsqu’ils effectuent une requête.
De plus, cette pratique permet aux moteurs de recherche de mettre à jour constamment leur proposition de pages.
Le processus de crawling expliqué
Comment les moteurs de recherche utilisent le crawling pour extraire et évaluer les mots

Comme vous avez pu le comprendre, les moteurs de recherche font appel à des robots d’indexation afin de parcourir le Web et découvrir de nouvelles pages. Les liens visités par ces robots sont explorés à partir de sitemaps et de sites web qui ont été visités lors de crawls prAlgorithme historique de Google évaluant l'importance d'une page selon ses backlinks. Toujours utilisé en interne.écédents. Pour expliquer le schéma ci-dessus, nous allons voir comment Google explore, traite et indexe les pages:
- ExplorationProcessus par lequel les robots des moteurs de recherche parcourent et analysent les pages web. : Tout d’abord, Google va découvrir une URLUniform Resource Locator. Adresse unique d'une page web. Une URL optimisée est courte, descriptive et contient le mot-clé. (cette découverte peut également être motivée directement par l’utilisateur lui-même). Il va ensuite l’ajouter à sa liste d’attente d’URL à crawler. GooglebotRobot d'exploration de Google qui parcourt le web pour découvrir et indexer les pages. va alors soumettre des requêtes GET à un serveur pour toutes les URL qui se trouvent dans cette file d’attente d’exploration et va enregistrer le contenu de la réponse. Il réalise cette action pour le HTML, le JavaScriptLangage de programmation web. Son mauvais usage peut bloquer l'indexation par les moteurs de recherche., le CSS, les fichiers images, etc.
- Traitement : Cette étape concerne tout d’abord l’ajout de nouvelles URL à la liste d’attente et qui proviennent des liens qui ont été trouvées dans le code HTML de la page explorée. Cela inclut aussi bien les URL de ressources (CSS et JavaScript) trouvées au sein des balises et les images qui sont quant à elles trouvées dans les balises
. Cependant, si le robot d’exploration tombe sur une balise
- Rendu : Pour ce qui est du rendu, Googlebot va exécuter du code JavaScript avec un navigateur Chromium sans header afin de mettre le doigt sur tout éventuel contenu dans le DOM (Document Object Model), mais pas spécialement la source HTML. Il le fait tout de même pour toutes les URL HTML.
- Indexation : Caffeine, l’indexeur de Google utilise les informations de Googlebot, les normalise, tente d’y donner un sens en précalculant certains éléments de classementPosition d'une page web dans les résultats de recherche pour une requête donnée. qui sont prêts à être diffusés dans les résultats de recherche.
Le processus d'extraction des mots sur une page web
L’extraction de mots est une étape capitale dans le processus de crawl de sites Web. En effet, les robots d’indexation parcourent le code HTML de la page visitée dans le but d’extraire des mots pour les indexer. Cependant, même pour les robots de Google, il est impossible de traiter certaines données comme le JavaScript ou encore les images à cause du manque de puissance de traitement nécessaire.
Les mots qui ont été extraits sont alors évalués pour être indexés en fonction de leur pertinence par rapport à la requête réalisée par l’utilisateur. Les mots-clésTerme ou expression que les utilisateurs saisissent dans un moteur de recherche. Base de toute stratégie SEO. les plus pertinents sont alors privilégiés dans le processus d’indexation. Ce dernier consiste à stocker, analyser et organiser le contenu présent dans les pages. Une page comportant des informations pertinentes sera par conséquent mieux classée que les autres.
Tout cela vous semble compliqué ? Faites appel à une agence SEO comme Slashr !
L'impact du Crawling sur le SEO
Comment le crawling affecte le classement des moteurs de recherche
Le crawling a un fort impact pour le SEO. En effet, le crawl est l’étape qui va déterminer quelles pages vont être indexées. Une des principales limites des crawlers est leur “manque de rapidité” face à toutes les pages qui sont créées en permanence. Ces derniers vont alors éviter de perdre du temps pour les pages qui ne sont pas valables pour répondre à des requêtes. L’objectif est plutôt de se consacrer aux pages pertinentes. En outre, toutes les pages chargées d’erreurs et pouvant porter atteinte à certains critères socio-géographiques. Par exemple, pour la requête “Tian An'men”, les informations ne seront pas traitées de la même manière si elle est faite sur Google ou Baidu qui est un moteur de recherche principalement utilisé en Chine.
Les backlinks de haute qualité et leur rôle dans le crawling
N’oublions pas le rôle que jouent les liens dans le processus de crawlings. En effet, comme énoncé précédemment, les robots se baladent de lien en lien afin de découvrir des pages. Par conséquent, plus ils sont de qualité et plus il sera probable que les pages en question soient indexées.
Les outils de crawl pour le SEO
Le crawl peut également être mise en place à la suite d’une initiative humaine dans le cadre du référencement SEO. Il est courant pour un consultant d’utiliser des outils de crawl comme Screaming Frog qui en est le leader. Ces derniers permettent d’identifier les facteurs qui peuvent impacter le référencement d’un site.
Gérer le budget Crawl pour optimiser le SEO
Comme vous avez certainement pu le comprendre, pour les moteurs de recherche comme Google, crawler un site demande beaucoup de ressources et ces dernières ne sont pas illimitées. Nous comptons la limite allouée au crawl d’un site en termes de temps. On appelle ça le budget de crawl. Il est donc primordial de gérer efficacement ce budget pour que les robots puissent explorer le plus de pages possible.
Comment gérer efficacement votre budget crawl
- Comprendre le processus de Crawling (cfMétrique Majestic mesurant la quantité de liens pointant vers un site.. parties précédentes)
- Optimiser le maillage interneEnsemble des liens entre les pages d'un même site. Distribue le jus SEO et guide les utilisateurs. : il s’agit de la manière dont les pages d’un même site sont liées entre elles.
- Éviter le contenu dupliqué: Dupliquer son contenu revient à faire analyser la même chose aux robots et ça impacte fortement le budget de crawlNombre de pages que Googlebot peut et veut crawler sur un site dans un temps donné.. Par exemple, les balises canoniques pour ne montrer qu’une version d’une page aux robots ou encore, pensez à désindexer les pages à faible potentiel d’acquisition comme les mentions légales, les CGV, etc.
La performance d’un site est primordiale dans le cadre d’un crawl par les robots d’exploration. En effet, plus le site est performant, plus il sera rapide et par conséquent, plus le nombre de pages visitées sera conséquent.
Même si nous n’avons pas l’emprise sur le budget de crawl alloué à notre site, ni même quelles pages vont être visitées (on peut tout de même l’orienter avec le robots.txt le maillage interne, etc.), il est possible de l’optimiser via plusieurs techniques. Tout d’abord, il vous est possible de réaliser au préalable un crawl prédictif de votre site avec Screaming FrogLogiciel de crawl permettant d'auditer techniquement un site web. par exemple afin de pouvoir venir modifier tous les éventuels problèmes qui pourraient nuire au budget de crawl.
Anecdote de l'équipe : la parte de budget crawl via bot trap
Une des pertes de budget crawl les plus fréquentes est le bot trap généré par la navigation à facette. Il arrive que cette dernière génère des liens qui peuvent être suivi par google vers des pages avec paramètres, qui peuvent se cumuler. De cette façon :
- Exemple.fr/t-shirt?bleu
- Exemple.fr/t-shirt?bleu&Accelerated Mobile Pages. Framework Google pour créer des pages mobiles ultra-rapides (moins utilisé aujourd'hui).;vert
- Exemple.fr/t-shirt?bleu&vert&tailleS
- Exemple.fr/t-shirt?bleu&vert&tailleS&tailleM
- etc
On peut au final arriver à des dizaines voir des centaines de paramètres qui s'enchainement, à multiplier par le nombre de pages listing et se retrouver avec des millions de pages parasites.
Une autre méthode, qui reste tout de même plutôt laborieuse, est de réaliser une analyse de logsFichiers enregistrant toutes les requêtes reçues par un serveur, permettant d'analyser le comportement des bots. et d’identifier quelles pages ont un trop faible ratio entre le nombre de visites par des utilisateurs et le nombre de visites par les robots d’exploration. Une fois que ces pages ont été identifiées, il suffit d’utiliser une des nombreuses méthodes pour cacher les liens à Google comme par exemple les d’obfusquer afin que la priorité soit donnée aux autres pages.
Besoin d'aide pour votre référencement naturelSearch Engine Optimization. Ensemble des techniques visant à améliorer le positionnement d'un site web dans les résultats naturels des moteurs de recherche. ? Faites appel à agence de référencement Google à Lille.
Suivre les statistiques des crawls de Google via la Search Console
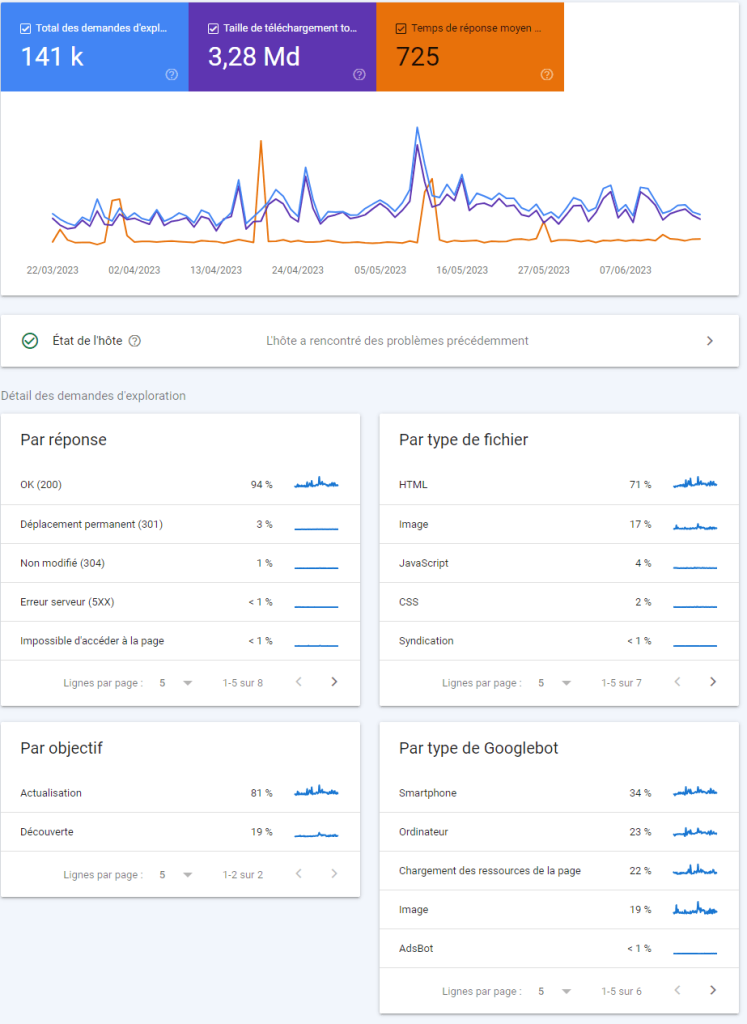
Afin de suivre et analyser les crawls réalisés par les robots de Google, rendez-vous sur la search consoleOutil gratuit Google pour surveiller et optimiser la présence d'un site dans les résultats de recherche. et cliquez sur paramètres, puis sur statistiques sur l’exploration et enfin sur ouvrir le rapport. Parmis toutes les données que vous pourrez trouver, il y en a 3 principaux qui sont:
Le graphique des tendances d’exploration
Il est composé de 3 métriques qui sont:
- Le total de nombre d’exploration,
- La taille de téléchargement et enfin
- Le temps de réponse moyen. Il faut ici vérifier s’il y a des pics significatifs ou des baisses afin de voir s’il y a un problème ou non avec le site ou son hébergement. Comme vous pouvez le constater sur l’image ci-dessus, il y a quelques pics sur le site qui sont dûs à de fortes influences ponctuelles ou un éventuel problème au niveau de l’hébergeur. Il est important de noter qu’il est préférable de conserver un temps de réponse moyen inférieur à 500Code HTTP indiquant une erreur côté serveur. Impacte négativement le crawl et l'expérience utilisateur.… contrairement à notre exemple.
Les détails de l’état de l’hôte
Cette métrique permet quant à elle de vérifier aisément la disponibilité générale du site au cours des 90 derniers jours. Elle est également composée de trois éléments qui sont:
- L’exploration par le robots.txtFichier texte à la racine d'un site indiquant aux robots quelles pages explorer ou ignorer.: il n’est pas obligatoire d’avoir un fichier robots.txt sur son site mais il est primordial de renvoyer un code de réponse valable comme le 200 ou le 404Code HTTP indiquant qu'une page n'existe pas. Trop d'erreurs 404 nuisent au crawl budget. en cas de recherche de ce dernier. Par exemple, s’il tombe sur une 503, il arrêtera directement de crawler le site.
- La résolution DNS
- La connectivité du serveur qui indique si le serveur n’a pas fourni la réponse complète ou s’il n’a tout simplement pas répondu. Si vous consultez des problèmes réguliers ou des pics, n’hésitez pas à contacter directement votre hébergeur.
La répartition des demandes d’exploration
Enfin, il permet de comprendre ce que les robots d’exploration de Google ont pu trouver sur le site. Elle est composée de 4 élément:
- Réponse
- Type de fichier
- Objectif
- Type de Googlebot
Tags
Clément Poletti
Expert SEO @ SLASHR
Passionné par le référencement naturel et les stratégies de croissance organique. Accompagne les entreprises dans leur visibilité sur les moteurs de recherche.
Articles recommandés
Positionnement sur les moteurs de recherche : définition et outils
Qu’est-ce que le positionnement sur les moteurs de recherche ? Définition Les pages web sont classifiées en fonction d’un mot-clé défini. Totalement dépendant d...
Google Discover : comment y apparaître et optimiser sa visibilité
Google Discover se caractérise par sa faculté à proposer aux internautes du contenu en rapport avec les requêtes déjà effectuées sur le moteur de recherche. Art...
Crawl budget SEO : Ce que Google explore… ou ignore
🧠 1. Le budget de crawl, c’est quoi au juste ? En SEO, pas d’indexation = pas de positionnement. Et pour qu’une page soit indexée, elle doit d’abord être vue p...


